J’ai eu la chance d’assister à une formation sur Cortana Intelligence Suite et SQL Data warehouse chez Microsoft Paris. La formation a couvert une série de modules sur le domaine de la Data science + Azure SQL Data Warehousing.
En tant que spécialiste BI, je me suis intéressé à la partie SQL Data Warehousing et j’ai plongé dans le monde fantastique d’Azure Data Warehouse (ADW) au cours des derniers jours.
Dans cet article, je voudrais parler de deux concepts dans Azure SQL Data warehouse : MPP & distribution. Ces concepts définissent la manière dont vos données sont réparties et traitées en parallèle :
1 – Massively Parallel Processing (MPP)
Commençons par l’architecture générale d’ADW.
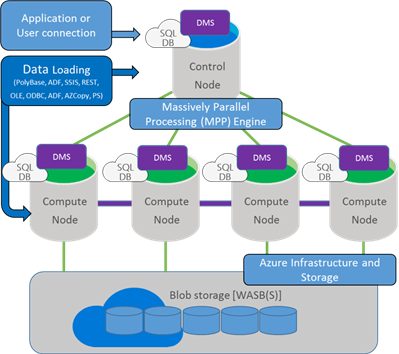
Conceptuellement, vous avez un nœud de contrôle sur lequel toutes les applications et les connexions interagissent, chacun interagit avec une multitude de nœuds de calcul.
Le nœud de contrôle récupère la requête en entrée ensuite il fait son analyse avant de l’envoyer aux nœuds de calcul. Les nœuds de calcul exécutent la requête sur leurs bases de données et renvoient les résultats au nœud de contrôle qui rassemble ces résultats.
Les données sont stockées dans Azure Blob storage et ne sont pas attachées aux nœuds de calcul. C’est pourquoi vous pouvez faire le Scale out, Scale in ou même suspendre votre ADW rapidement sans perdre de données.
ADW divise les données entre 60 bases de données. Tout le temps, indépendamment de ce que vous faites. C’est une constante.
Sachant que vous pouvez changer le nombre de nœuds de calcul indirectement en demandant plus d’Unité d’entrepôt de données (DWU) sur votre instance d’ADW.
Les bases de données ADW se mutualisent d’une manière implicite sur les nœuds de calcul. Il est assez facile, maintenant que vous savez qu’il y en a 60, de déduire le nombre de nœuds de calcul de l’Unité de stockage de données dédiée (DWU) en utilisant le tableau suivant :
| DWU | # Compute Nodes | # DB per node |
|---|---|---|
| 100 | 1 | 60 |
| 200 | 2 | 30 |
| 300 | 3 | 20 |
| 400 | 4 | 15 |
| 500 | 5 | 12 |
| 600 | 6 | 10 |
| 1000 | 10 | 6 |
| 1200 | 12 | 5 |
| 1500 | 15 | 4 |
| 2000 | 20 | 3 |
| 3000 | 30 | 2 |
| 6000 | 60 | 1 |
2 – Distribution
Il faut savoir que les données que vous chargez dans ADW sont stockées dans 60 bases de données. Quelles données sont stockées dans quelle base de données?
Normalement, avec une requête SELECT simple sur une table et des données distribuées uniformément, on ne devra pas se soucier, non? La requête sera envoyée aux nœuds de calcul, ils effectueront la requête sur chaque base de données et le résultat sera fusionné ensemble par le nœud de contrôle.
Cependant, une fois que vous commencez à joindre des données à partir de plusieurs tables, ADW devra faire du Data Movement, en d’autre terme il va balancer des données autour d’une base de données à l’autre afin de joindre les données. Il est impossible d’éviter ce fonctionnement en général, mais vous devriez essayer de le minimiser pour obtenir de meilleures performances.
L’emplacement des données est contrôlé par l’attribut de distribution de vos tables. Par défaut, les tables sont distribuées en mode round robin: les données vont d’abord à la base de données 1 puis 2, puis à 3 …
Vous pouvez contrôler un peu où vont vos données en utilisant la méthode de distribution de hachage. Grâce à cette méthode, vous pouvez spécifiez lors de la création de votre table, que vous souhaitez utiliser l’algorithme de hachage et la colonne à utiliser. Ce qui garantit que les lignes de données avec la même valeur de colonne de hachage se retrouveront dans la même table. Toutefois il ne garantit pas qu’une valeur de colonne de deux hachages finira dans la même base de données.
Alors, regardons un exemple simple d’une table distribuée en round-robin:
CREATE TABLE [dbo].DimProduct ( ProductID INT NOT NULL, ProductName VARCHAR(50) NOT NULL, Price DECIMAL(5,2) NOT NULL, CategoryID INT NOT NULL ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN )
Et maintenant avec un algorithme de hachage:
CREATE TABLE [dbo].DimProduct ( ProductID INT NOT NULL, ProductName VARCHAR(50) NOT NULL, Price DECIMAL(5,2) NOT NULL, CategoryID INT NOT NULL ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH(CategoryID) )
Dans cette partie , j’ai précisé que le hachage soit pris de la colonne CategoryID. Ainsi, tous les produits d’une même catégorie seront stockés dans la même base de données.
Alors qu’est ce que j’ai gagné en s’assurant que les produits des mêmes catégories sont stockés dans la même DB … ?
Si je veux obtenir la somme du nombre de produits par catégorie, je peux maintenant le faire sans mouvement de données parce que je suis sûr que les lignes pour une catégorie donnée seront tous dans la même base de données.
De plus, si je veux joindre des données d’une autre table sur ID de catégorie, cette jointure peut se produire “localement” si l’autre table a également une distribution de hachage sur l’ID de catégorie. Vous devez penser au type de requêtes que vous allez avoir et également vous assurer que les données seront réparties uniformément.
Il est recommandé d’utiliser le contrôle de la distribution sur des colonnes qui ne sont pas mis à jour (la colonne de hachage ne peut pas être mise à jour) et de répartir les données de manière égale, en évitant les biais de données afin de minimiser le mouvement des données.
Résumé
Grosso modo, j’ai essayé d’expliquer les différentes façons dont vos données sont distribuées autour d’Azure Data Warehouse (ADW).
J’espère que ces explications pourront vous être utiles sur vos projets et que cela vous donne une image claire de la façon dont les nœuds de calcul accèdent à vos données et comment vous pouvez contrôler leur distribution.
Leave a comment