La différence entre l’index Clustered et Non-clustered dans une base de données est l’une des questions les plus populaires en SQL.
Les index sont un concept très important, il rend l’exécution de vos requêtes rapide et si vous comparez une requête SELECT qui utilise une colonne indexée à celle qui n’a pas, vous verrez une grande différence dans les performances.
L’index est une structure de type B-Tree associé à une table ou une vue :
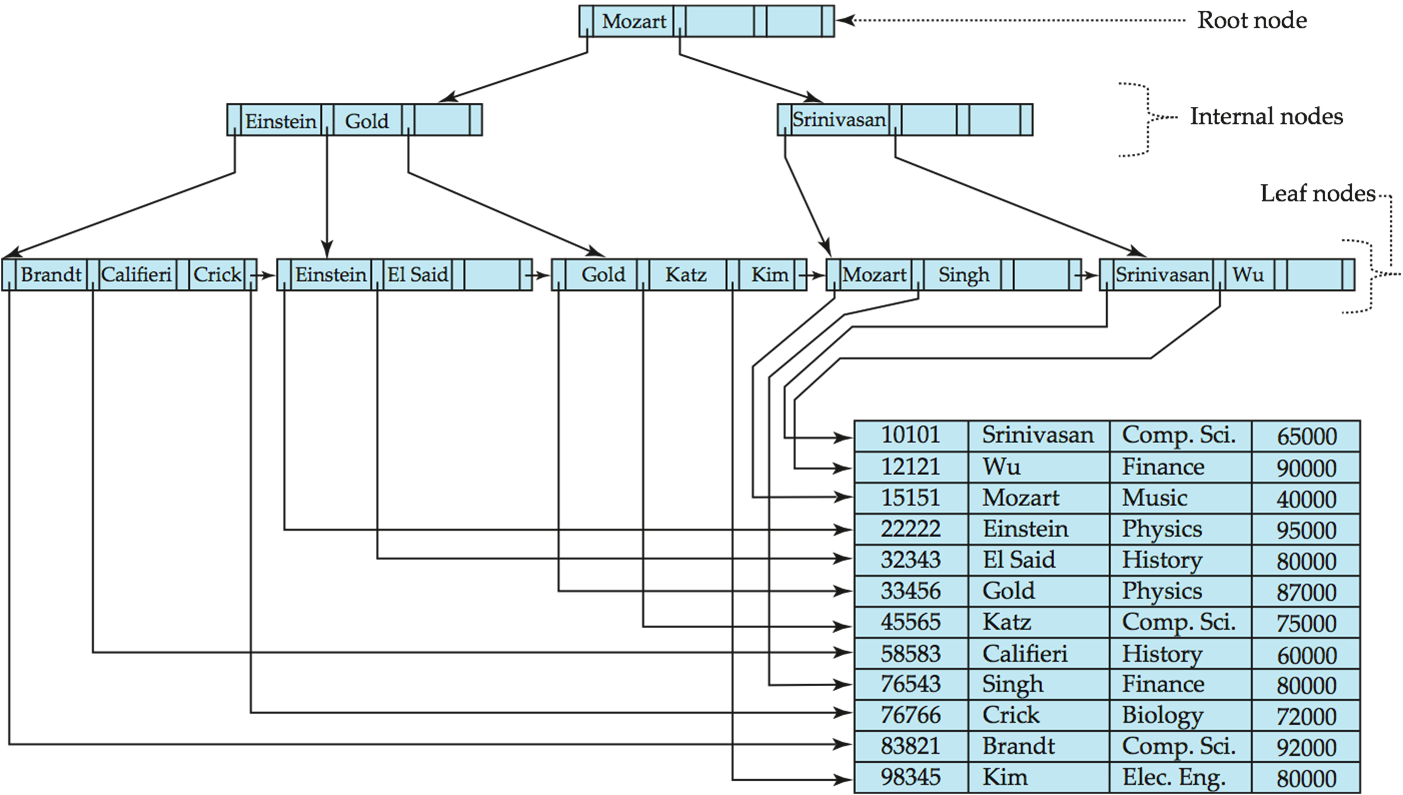
L’index référence des valeurs de clés et permet de retrouver par dichotomie une valeur déterminée plus vite.
-
Index Cluster
Les index Cluster trient et stockent les lignes de données en fonction de leurs valeurs des colonnes incluses dans la définition de l’index, en ce sens un index cluster est un doublon de la table. Il ne peut y avoir qu’un seul index par table car les lignes de données ne peuvent être triées que dans un seul ordre.
Dans un index cluster, les internal nodes de l’arbre de tri contiennent les valeurs de la clé (et un RowID), selon l’ordre physique de celle-ci, et seul le niveau leaf contient les pages de données de la table.
-
Index Non-Cluster
Les index non-cluster contiennent les valeurs de clé de l’index non-cluster et chaque entrée de valeur de clé dispose d’un pointeur vers les lignes de données qui contiennent la valeur clé.
Le pointeur situé entre une ligne d’un index non-cluster et une ligne de données est appelé un localisateur de ligne. Le localisateur de ligne peut être soit sous la forme de ROWID s’il n’y a pas d’index cluster sur la table, soit en pointant avec la valeur clé de l’index cluster s’il existe.
Il peut y avoir plusieurs indexes non-cluster sur une table.
Un index non-cluster est ordonné suivant l’ordre logique des valeurs de sa clé (et un KeyID), et son niveau leaf ne contient pas les pages de données, mais les lignes de l’index cluster.
Leave a comment